I just hope that Cray was on Ivytown. Opteron can't keep up. Xeon + Xeon PHI owns the #1 supercomputer in the world, and that is probably not going to change anytime soon.
Unnamed MLB team purchases Cray supercomputer
- Thread starter 67WasBest
- Start date
AlNipper49 said:Again, its probably not a standalone. Their most common application these days is as part of clusters, facilitating (or diverting) those same bottlenecks that you mention.
Crays aren't like 30 years ago. They're 'just another server' - outside of the aforementioned architectural differences - these days. You basically but them so that you can scale you commodity hardware easier in both operational and peak capacities. Think of it as buying a point guard in the NBA. You're not starting a team with just one player, the point guard, or conversely you're not starting it with five PGs.
Clearly someone wants data fast, that's the takeaway from this. It would he really cool if there was a behind-the-scenes arms race. I'm also sure that some teams may agree with you and are going Cray-less designs -- this is largely a result of the MSA signed between the team and Cray. Cray's announcement that a team is using them has material value.
They're not just part of clusters; they are clusters. They're clusters with low latency, high throughput networking fabric. My curiousity was about what type of jobs they'd be running which would require the fast interconnects. I think you're right in that it's probably related to the MSA signed between them and Cray. Cray took over Blue Waters at UIUC after IBM backed out because the maintenence costs would be too high while I was there for my PhD. Most of the large scale academic and national lab supercomputers are loss leaders for the companies building them.
Plympton91 said:One is personal preference. I get enough statistical analysis in my day job for 2 lifetimes and really don't like it much intruding on my sports viewing.
Second is because I'd rather watch David Ortiz hit line drives to right field than ground balls past an empty 3B.
Third shifting also can make the pitcher better than he should be.
In short, I don't want some stat geek like affecting the outcome of a game anymore than I want a bad umpire call affecting the game. Let the players talents shine through. Like I said, I understand that a good player can beat a shift with a well placed ground ball, but my response is a golf clap as I remain seated and take a sip of an adult beverage. The reaction to Ortiz granny in the playoffs was a bit different.
To the first bolded bit: I'd rather watch David Ortiz use his skills and intelligence to defeat the other team's strategy, whatever it is. Scorching line drives are cool. Well-placed dribblers or even bunts are cool. What's enjoyable is the strategic battle and watching players use their talent to win it. (And the scorching line drive is implied by the shift; without the threat of it, the shift isn't there. I can enjoy it as a hypothetical event, and also enjoy whatever really happens.)
To the second: Who defines how good a pitcher "should" be? Good pitching has a lot of dimensions, and one of them is taking advantage of good (and smartly managed) defense. A shift lowers some risks and increases others. There's skill involved in making good use of it. It may make the pitcher's job easier, but to take full advantage a pitcher still needs intelligence and command. (Or, what terrisus said.)
To the "which team" speculations, I agree that the Astros and Cubs both make sense. Might the Pirates also be a possibility? They were mired in total mediocrity five years ago and would have had little practical use for a tool like this (whoop-de-do, we win 70 games instead of 65!). And they would qualify as "not the kind of franchise you'd expect", in terms of big-market, big-spending types.
finnVT said:I'm trying to figure out what you'd need a cray for that you couldn't do for a fraction of the cost with an off-the-shelf cpu/gpu cluster. i would think that nearly any sort of statistical analysis would be performed plenty fast on the latter, or could be performed ahead of time. i almost think you'd have to be doing some serious physics modeling for it to be worth it (i.e., how real-time conditions like humidity and wind interact with the speed & spin of the pitch when hit given the bat speed and angle used by the current hitter, in order to, say, know what pitches are going to be most effective at inducing a ground ball).
From last summer's seminar schedule--check out Sunday at 2:00pm.
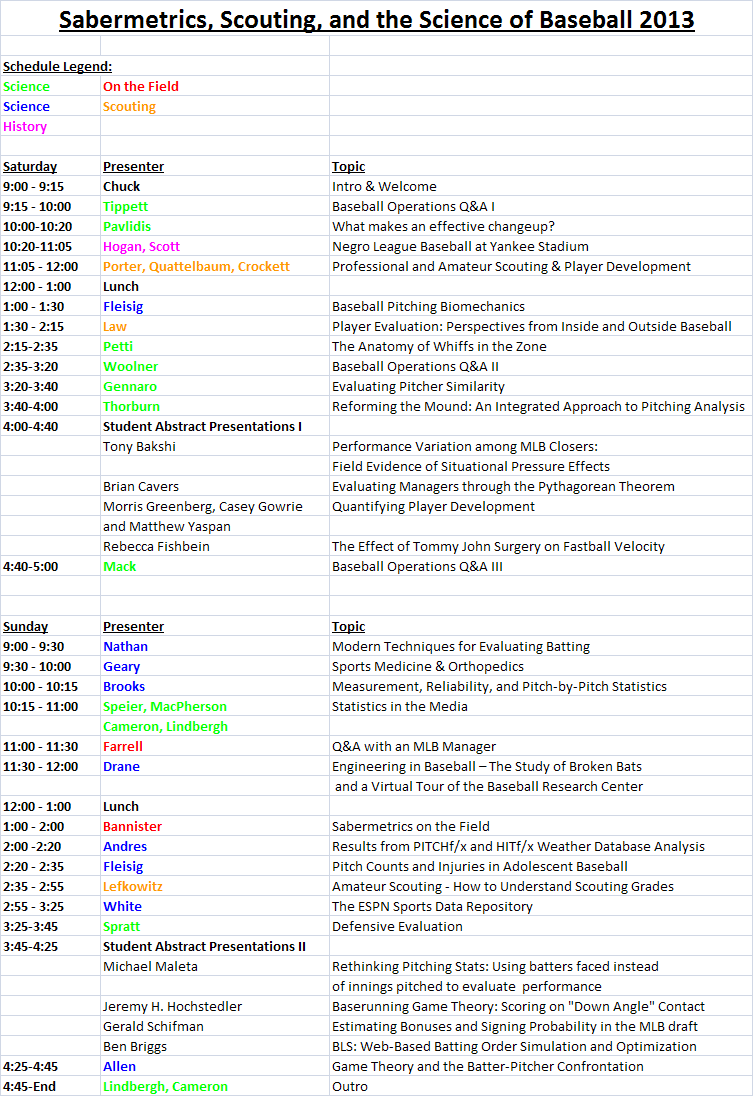
If I recall correctly, the talk was mostly about temperature and humidity and it's affect on how both pitched and batted balls traveled.
You may also note at 9am that morning, SoSH's own Allan Nathan presented. He discussed lots of stuff on batted ball trajectories and concluded that, based on his findings, he needed to look at something about bitters who put backspin on the ball and factoring that in would improve the accuracy of the statistical analysis.
ean611 said:I just hope that Cray was on Ivytown. Opteron can't keep up. Xeon + Xeon PHI owns the #1 supercomputer in the world, and that is probably not going to change anytime soon.
The #2 is a Cray:
18,688 AMD Opteron 6274 16-core CPUs
18,688 Nvidia Tesla K20X GPUs
Somewhere between 17-27 petaFLOPs
http://en.wikipedia.org/wiki/Titan_(supercomputer)
But that's just on raw floating point ops. Some of the IBMs smoke both of these machines on interconnect speed--Blue Gene Q machines hold 9 of the top 11 spots in that metric, including the top 3. For a lot of real world applications that's more important than raw flops.
Slashdot just linked an article on this: http://www.hpcwire.com/2014/04/03/inside-major-league-baseballs-hypothesis-machine/

“Urika is unique in that it’s a global shared memory machine that lets you look at data in an unpartitioned fashion. This is very critical if you’re looking at graphs, which by nature are unpredictable. Further, certain graphs are non-partitionable—and if you do partition it, it changes the result of a query,” White explained. “There is no MapReduce job or partitioning that will do anything but fracture the graph to a point where it’s no longer reconstructable—and even for those you can reconstruct, it would take a lot of compute power.” Where this works is with memory-bound problems versus those that are compute-bound, in other words.
Urika is also fitting for the big data of MLB given the disparate data sets required to piece together a best-case-scenario for team leaders. There are lots of sources and combining that data requires a data structure that allows for federated queries. This is exactly the reason big pharma and a few others find RDF machines useful (in the case using SPARQL queries). “You could go ahead an do the equivalent of a hundred-way join from a relational database—the question is, how big of a dataset can you do that against?” asked White. “Unless you have something like Urika, which has the ability to do it memory and with massive multi-threading, you’re not able to look at enough data.” He said that when compared to what they’re doing inside Urika, for normal relational databases, this would be the equivalent of a 30-50 way join. Pulling from the large shared memory pool using SPARQL queries offers a more seamless blending of conditions to hypothesize against. And herein lies the selling point for operational budget-constrained MLB.
An article on the complexity of the replay system
http://www.sportsonearth.com/article/70183162/major-league-baseball-instant-replay-may-be-overwhelming
Lets go all Person of Interest here:
If we connect the Cray to the replay system and add facial recognition, how far are we from real time tendency prediction that can be forwarded to the Google glasses that the manager or hitter is wearing? How about have colored lights in center field above the pitchers shoulder that turn on based on the pitchers grip seen on the baseball at release? Blue means split, Green means Fastball etc..
http://www.sportsonearth.com/article/70183162/major-league-baseball-instant-replay-may-be-overwhelming
Lets go all Person of Interest here:
If we connect the Cray to the replay system and add facial recognition, how far are we from real time tendency prediction that can be forwarded to the Google glasses that the manager or hitter is wearing? How about have colored lights in center field above the pitchers shoulder that turn on based on the pitchers grip seen on the baseball at release? Blue means split, Green means Fastball etc..